I manage my MP3 collection with my own hand-written tool because I already have a big database with information about the bands and songs.
One of the features of the playlist manager is to specify custom SQL code to select any of the 30,000+ songs in the database for the playlist.
This allows me to have playlists like:
- Any songs released in 1986
- Any songs by bands from Sweden before 1993
- Any songs released on "Sarah Records" on 10" vinyl.
- Songs by bands added to the database in the last 12 months
You get the idea.
For my next big trip I was thinking of which songs to take along. I only have about 40 Gig space for music on my player, which is enough for roughly 10,000 files.
One idea was to take songs from my all-time favourite bands, but the filter already returns over 10,000 songs and I wanted to add some other tracks as well. So I said, lets take just 50 songs from each of my 250 favourite bands. Which songs? I don't care, they can be random, but I don't want a song twice, regardless of the fact that I have duplicate MP3s because they have been released on multiple albums or compilations. The SQL to do this was not super simple, so that's why I documented here.
To keep things simpler, I first created two views, the first one filters out duplicate song titles:
CREATE VIEW UniqueSongs AS SELECT MIN(FileID) AS FileId, Title, BandKey FROM SoundFiles GROUP BY Title, BandKey
the second one returns my favourite bands:
CREATE VIEW FavouriteBands AS SELECT BandKey FROM Bands WHERE Rank > 8
Now to the main query, which uses a Common Table Expression:
WITH CTE AS ( SELECT Row_Number() OVER (Partition BY b.BandKey ORDER BY ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT))) As RowNo, u.FileId FROM UniqueSongs u INNER JOIN FavouriteBands b ON b.BandKey = u.BandKey ) SELECT FileName, RootFolder + Location as Location, BandName, Title, Duration FROM SoundFiles WHERE FileId IN ( SELECT FileId FROM CTE WHERE RowNo <= 50 )
The first SELECT gets all the MP3s for my favourite bands,
ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT)))
just returns a random number which we order by, so we get a different set of up to 50 songs each time we run the query.
The really cool part here is:
Row_Number() OVER (Partition BY b.BandKey ORDER BY
We partition our data by the BandKey in a random order and each row gets an new row number one higher than the previous one. For each new band, the row_number is reset to 1.
Here's how that looks for 3 songs per band:
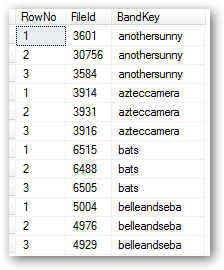
The second SELECT gets the actual data required to build a playlist, the interesting part is in the sub-select in the WHERE clause:
SELECT FileId FROM CTE WHERE RowNo <= 50
Here we use our common table expression from above to get the first 50 fileIDs per band. Remember the RowNo is a continues increasing number, so filtering for anything less 51, gets us the first 50. Cool!